

GANとは
GAN(敵対的生成ネットワーク)とは、Generative Adversarial Networkの略語で、AIアルゴリズムの一種です。
用意されたデータから特徴を学習し、擬似的なデータを生成することができる生成モデルです。GANは、Goodfellowらによって2014年に発表されました。
下の図は、実際にGANが生成した画像を示しています。黄色の枠で囲われたのが事前に用意された訓練データであり、そのほかがGANの生成した偽物の画像たちです。こういった擬似的なデータを作り出すことを「生成」と言い、それを実現するモデルのことを「生成モデル」と呼びます。

GANの構造と学習
GANの具体的な構造を下の図に示しました。GANはジェネレーター(Generator)とディスクリミネーター(Discriminator)という2 つのブロックで構成されています。
いずれのブロックもニューラルネットワークが用いられているため、誤差逆伝播法による学習が可能です。
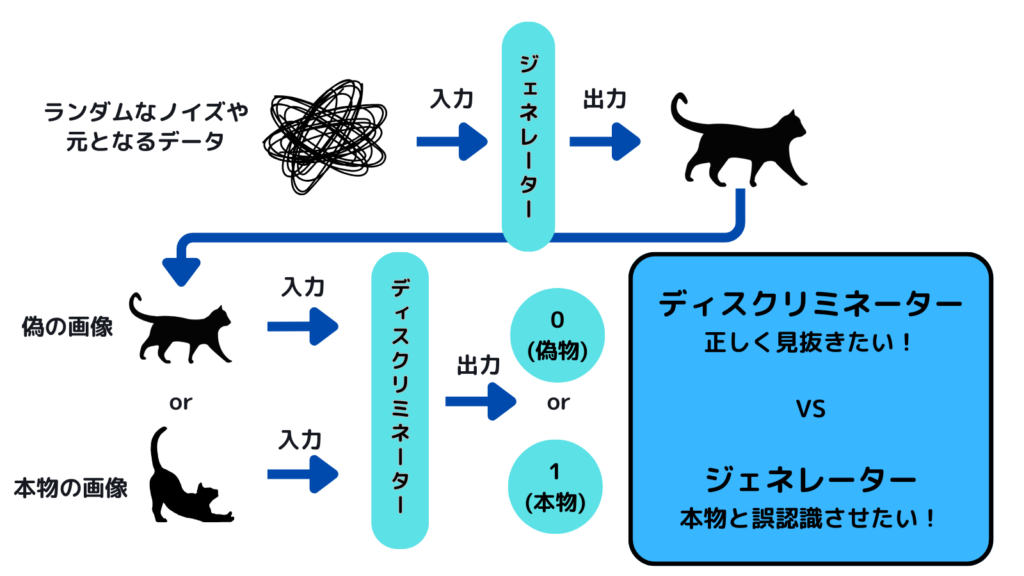
ジェネレーター
ジェネレーター部分は「何らかの数値を(基本は乱数)を入力として受け取り、その数値に基づいて新しいデータを出力」します。
生成モデルでいうところの「確率分布」→「入力」がジェネレーターの部分に対応します。
一般に、入力として受け取る数値には、正規分布などの確率分布に従う乱数が用いられます。
ディスクリミネーター
ディスクリミネーター部分は「入力されたデータがジェネレーターの生成した偽物か、あるいは訓練データとして用意された本物か」を判別します。
生成モデルでいうところの「識別」が、このディスクリミネーターに対応します。
GANの学習
GANの学習では、
ジェネレーターは「ディスクリミネーターを騙せるような精巧な偽物を作ることができる」ように、
ディスクリミネーターは「用意された本物とジェネレーターが作り出した偽物を区別できる」ように学習していきます。
ジェネレーターとディスクリミネーターの関係が敵対的であることから、Generative Adversarial Network「敵対的生成ネットワーク」という名がつけられました。
ジェネレーターとディスクリミネーターはそれぞれの目的に従って交互に最適化されます。最終的に、ジェネレーターが生成する偽物が、本物と区別できないようなデータになっていればGANの学習は成功といえます。
生成AIについて詳しく学びたい方はこちらの塾がおすすめ!
GANの活用方法
2014年にGoodfellowらがGANを発表して以来、世界中の様々な研究者がGANの派生系を考案しました。そのGANの派生系は、数百以上あると言われています。 GANの派生系ができることの例を以下に示します。
- 画質の高い画像を生成する
低画質の画像を入力として受け取り、その画像を高画質にした画像を出力することができます。
- テキストから画像を生成する
テキストを入力として受け取り、そのテキストに基づく画像を生成することができます。この技術は、脚本からアニメーションを制作する場面など、さまざまな場面への活用が期待されています。
- 画像をスタイル変換する
簡単な線画を入力として受け取り、その線画をアニメーション作家が描いた絵のように変換し出力することができます。
- 画像とテキストを合成する
画像とテキストを入力として受け取り、それらを合成して新たな画像を生成し出力することができます。
この他にも、
- 動画生成
- 画像の欠損補完
- 画像のモザイク除去
- 音声生成
- 異常検知
- 2D画像の3D化
など、さまざまなGANの派生系が提案されています。
GANの発展と種類
GANは、先述したとおり、Goodfellowらを始めとする研究者たちが2つのニューラルネットワークを競い合わせながら学習させるという方法を2014年に論文で発表したことがはじまりです。
近年では、より効果的に敵対的生成ネットワーク(GAN)を活用するためのさまざまな応用研究が進められています。
GANの派生系は、前述した通り、数百以上あると言われています。
それら全てを紹介しきることは流石にできないので、ここではその中の「DCCAN」、「CycleGAN」、「StyleGAN」の3つのアルゴリズムや活用事例について、詳しく解説します。
DCGAN
2015年に発表されたDCGAN(Deep Convolutional GAN)は、AIの画像認識でよく使われるニューラルネットワーク(CNN)技術を応用したものです。ディープラーニング(深層学習)のひとつでもあります。
最初に誕生したオリジナルの敵対的生成ネットワーク(GAN)は、テキストデータの生成がメインでしたが、DCGANは画像生成が得意な点が特徴です。昨今、数多く登場している画像生成サービスに使われているGAN技術は、DCGANが中心となっています。
オリジナルの敵対的生成ネットワーク(GAN)に比べて、DCGANが生成する画像は鮮明で画質が高いため、品質の高い画像生成を行いたい場合は、DCGANの活用が有効です。また、従来のGANに比べると学習が安定化されており、与えたデータに対してシンプルな画像の生成が可能になっています。
教師なし学習×ニューラルネットワークの発展形として、多くの場面で注目されています。
この新しい学習方法が提案されて以降、GANは多くの研究者の研究対象となりました。GANの派生系は、前述した通り、数百以上あると言われております。
CycleGAN
2017年に発表されたCycleGANとは、一言でいうと、画像のスタイル変換を得意とするディープラーニングモデルです。
スタイル変換とは、データの外見的特徴を変換することです。「画像から画像への翻訳」(Image-to-Image Translation)とも呼ばれます。
より詳しく説明すると、CycleGANは関連性のない2枚の画像を使用して、AIに双方の画像の特徴を寄せ合い、新たな画像を生成する敵対的生成ネットワーク(GAN)です。
例えば風景画像とゴッホの画像を用意し、CycleGAN技術を取り入れることで、「ゴッホ風の風景画像」を生成できます。

また、朝の風景画像と夜の画像を与えることで、「夜の風景画像」を生成するなどの例も挙げられます。2枚の画像の特徴を寄せ合う時に構成するネットワークがサイクル状であることから、「CycleGAN」と呼ばれています。
他にも有名な例として、馬の画像をシマウマの画像へ変換することと、シマウマの画像を馬の画像に変換することを、1つのモデルで実現できます。

CycleGANの特徴は、「条件付けができること」にあります。例えば、AIに0~9の数字をあらかじめ学習させてラベル付けを行っておくと、「数字の9を生成して」と命令するだけで、数字の9の画像を生成できるようになります。
冒頭の例で言えば、「ゴッホ風の絵」とはどのようなものなのかをAIが学習することで、「ゴッホ風の夕暮れの丘の画像を生成して」と命じるだけで、イメージに沿った画像が生成されるようになるのです。
StyleGAN
2018年に発表されたStyleGANは、高解像度の画像を生成する敵対的生成ネットワーク(GAN)です。StyleGANを活用すると、本物とは見分けが付かないような人間の顔など、リアルな画像を生成できます。
リアリティが高すぎるSyleGANの登場によって、「写真は証拠として役に立たなくなる」とまで言われています。
下の画像はStyleGANにより生成した、すべて存在しない人物の顔写真であり、StyleGANによって生み出されたものです。

StyleGANの学習では、最初、低い解像度の画像を学んでいきます。低い解像度の学習を終えると、次はより高い解像度の画像を学んでいき、最終的に肉眼では見分けが付かないような精巧な画像を生成できるようになるという仕組みです。
StyleGANでは、データに潜むノイズをGeneratorとは別の空間で抽出し、その結果をメインの空間に反映させることで、効率的かつ精度の高い学習を可能にしています。現在では、書記のStyleGANのデメリットを修正した「StyleGAN2」というモデルが使用されています。
GANの活用事例
GANを実際に活用されている企業やサービスは多数あります。ここからは、GANの活用事例を2つ紹介します。
アクションゲーム「パックマン」
大手GPUメーカーのNVIDIAは2020年、ナムコの生誕40周年を記念して、GANを使ってパックマンを完全再現したことを発表しました。この完全再現には、GameGANと命名された技術が使われました。
NVIDIAのGameGANは、基本となるゲームエンジンなしで、完全に機能するパックマンを生成することができます。GameGANは、学習を通して動かない背景と動くキャラクターを区別することができます。
ゲームの完全再現に成功すると、背景を他のものに差し替えて新たなゲームステージを生成することも可能です。この技術を使えば、今後コーディングすることなく新規ゲームステージを生成することが可能となるため、ゲーム業界で大きなニュースとなりました。
Mad Street Den のファッション AI
Mad Street Den Incが開発するAI「Vue,ai」は、AIを活用した小売業向けの総合ソリューションプラットフォームです。
「Vue,ai」では、ファッションモデルに洋服やアクセサリーを試着させた画像を生成できます。
GANはなぜ廃れたのか?
さて、ここまでGANを紹介してきましたが、実はGANはその派生モデルである「拡散モデル」に立場を奪われており、ほぼ見かけることはなくなっています。
その大きな理由の一つが、GANは拡散モデルとは異なり、「モード崩壊」を起こすからです。
モード崩壊とは?
モード崩壊とは、簡単に言うと、AIが多様な画像やデータを生成するはずが、似たり寄ったりのものばかり作ってしまう状態のことを言います。
例えば、絵を描くロボットにいろいろな動物の絵を描かせたいと思っています。でも、モード崩壊が起きると、このロボットが描くのは「猫」の絵ばかりで、他の動物の絵は描かなくなってしまうんです。本来は犬や鳥、ウサギも描けるはずなのに、なぜか「猫」しか描かないというわけです。
これが起きると、GANが持っている能力をフルに活かせていないことになります。多様性が失われるため、使い道が限られてしまうのです。
モード崩壊が起こる主な原因は、GANの二つの部分、生成器(ジェネレーター)と識別器(ディスクリミネーター)の訓練のバランスが取れていないことにあります。
GANは、生成器がデータを作り出し、識別器がそのデータが本物か偽物かを判定します。理想的には、生成器は識別器をだますほどリアルなデータを生成するようになり、識別器もそれを見分ける能力を向上させます。しかし、以下のような問題が起こることがあります
- 識別器の過学習
識別器があまりにも効果的になると、生成器が出力する多様なデータの多くを簡単に見分けてしまうことがあります。これにより、生成器が識別器に通るためには限られた種類のデータに集中しなければならなくなり、結果として多様性が失われてしまいます。
- 最適ではない点への収束
生成器が特定のデータポイントでのみ高い評価を受けるような局所的な最適解に収束する場合、その結果として出力が似通ったものに限られることがあります。これは、生成器が識別器を最も簡単に騙せる特定のパターンや特徴を見つけ出してしまうためです。
- 報酬の罠
生成器が最も効果的に識別器を騙す方法を見つけ出すと、その方法を繰り返すことで最大の報酬(識別器を騙すこと)を得られるため、他の可能性を探求しなくなることがあります。これにより、生成されるデータの多様性が低下します。
このように、GANのトレーニング過程において、識別器と生成器の間の微妙なバランスを保つことが非常に重要であり、そのバランスが崩れるとモード崩壊が発生しやすくなります。そのため、訓練プロセスを慎重に管理し、調整を行う必要があったのです。当然これでは開発に時間がかかるため、新しいモデルに移行していった、というわけです。
生成AIを効率よく学習する方法
生成AIツールは日々進化しており、Web上の情報もすぐに古くなってしまいます。そのため、生成AIについて独学で学ぶのはあまりお勧めできません。
おすすめの勉強法は、生成AIのプロに直接「これがやりたいんですけどどうすればいいですか?」と聞くことです。
しかし、そんな都合よく、身近に生成AIのプロなんていないですよね。
そこでお勧めなのが、「イナズマ塾」です。
イナズマ塾の最大の特徴は、「講座数の豊富さ」と「コスパの良さ」です。料金が業界の相場(30万円)の半額でありながら、受講可能な講座数も100を超えます。
イナズマ塾は日本屈指の理系大学 東工大出身の現役AIエンジニアとAI起業家が中心となってカリキュラムを作成しているため、大学レベルの最新のAI技術についてわかりやすく学べます。
また、講座内容も「パワポ資料の自動生成」「チャットボットの作成」といったビジネスで使える実践的なものばかり。
さらに、コースを修了すると、「AI活用プロフェッショナル認定」が取得可能!!!
なお、当サイト限定の特典として、無料面談フォーム入力時に下記の招待コードを入力すると、受講料が20%OFFになります!!!
イナズマ塾に入塾を検討されている方は、ぜひ、こちらの割引をご利用ください!!
招待コード:STAIT2025
「イナズマ塾」に関する詳しい内容はこちらの記事で紹介をしています!



コメント